よし、ネスペの願書送ったっと。しかし、来月はかなり金欠病陥りそう(ToT)
…ま、頭が痛くなることはどっかに置いといて(笑)、この前のバイトネタの続き。
動作的にはこの前考えてた構想で上手くいったんだけど、過去ログの検索がすこぶる遅い。2000件探し出すのに100秒以上かかってる〜(--#
原因は条件に合うデータを探す関数が1回に50ミリ秒(1ミリ秒=1/1000秒)かかってるのが大きいらしい。最初はファイルアクセスが遅いのかな?と思ったんけど、5ミリ秒程度で終わってるから別だな。根掘り葉掘り(?)調べた結果、どうやら日時の加減算をする処理が一番ネックになってるようなんよ。ログデータの時間形式はUNIXのtime形式。これって1970年1月1日の0時00分00秒からの秒数で時間を表している。さらにUTC(世界協定時刻)が基準なんで、日本の場合は9時間ずれるっと。こうやって計算すれば、例えば、2000年7月27日12時00分00秒、は「964666800」って具合。でも、これじゃ使いにくいんで、普通の時間との変換が必要になってくる。この計算をするのに DateAdd、DateDiff ていうVBの関数を使ってるんけど、こいつがどうも遅い。検索中何度も使ってるんを見直して極力使わないようにしただけで、なんと20ミリ秒に改善♪これでやっと2000件でオーバーヘッド入れて50秒。ん〜、まだ遅いなぁ。
他にもないかなぁ、って探してる時にふと思ったんよ。処理の至る所で文字型のデータを整数型、具体的に言えば Long型に変換してるんけど、Val で変換するのと CLng で変換するのって、どっちが速いん?ってね。CLng って昔のバージョンにはなかったけど、最近はもっぱら CLng 使ってるかな。単純に考えると、CLng はシンプルに Longに変換するだけで、Val は「文字列に含まれる数値を適切なデータ型に変換」、だから CLng のが速いん?って思った。けど、ちょっと確信なさげ。VBって型に関してアバウトだからわざわざ変換しなくてもOKだったりするから、こういう時はかえって面倒なだけ。結局、
検証プログラムを作成して比べてみた。
ソース見れば分かるけど、めちゃ単純。いいの、こういうのは単純でもぉ〜!(笑)
結果はやっぱり CLng のが速かった(^^) Pentium200MHzで Val のは20秒、CLng のは15秒 。さて、これでちょっとは速くなるかな。さらなる挑戦は続く!?(笑)
#最終的には2000件 - 15秒まで改善(^_^)v
そろそろネスペ(ネットワークスペシャリスト、NSP)の勉強しないとやばいな、ってことで、金曜日の帰りに本屋に寄って過去文集買ってきた。急いでいたんで、パラパラとしか内容みないでフィーリングで買ったんけど、こういう買い方すると問題集はたいていはずれるんだよね(^_^;;
沖電気(発行は
リックテレコム)の「最短攻略 ネットワークスペシャリスト問題集」っての。問題集だから、やっぱり補完するテキストも欲しいところかな、初めてのトライだしさ。んで早速少しやってみた。午前問題は、う〜む、2種共通問題の出来が相変わらず悪いかも。2種受けたばかりだから、まだ
少しは覚えてるけど(笑)午後問題もちょっとやったんだけど、午後問題は、…日本語を正しく理解するのは難しいね。間違って解釈したら、問題解く以前の問題だ〜
こんな調子なんで、先は思いやられるでしょう(笑)
そう、話題の
PC搭載可能PCデスク、ってなんか表現が微妙やな。金曜に名駅TSUKUMOで現物見たんけど、個人的には凄く好きだな♪スペースの有効利用だと思うし、インテリア性も高い。さらにCPUファンがくるくるしてるのが一目瞭然なわけだから、PCの点検効果も抜群?(笑)
しかし、値段がちょっとね。あれで安ければかなり考えさせられるかも。
たまにはバイトネタでも。今作ってるんは、あるシステムのログを表示するプログラム。詳しいことは知らないけど、UNIX上でシステムコアが動作していて、そのログをWindowsNTマシンのファイルに落とすらしい。それでそのNT上でログを見れるようにしたい、というわけ。ただ、動作条件・仕様が、
- データはリングファイル構成
- データ件数は最大10万件
- データはリアルタイムに書き換えられる。その間隔は1秒以下の場合あり
- 特定のデータを監視して、そのデータが更新された場合に即座に画面上でも更新する
- 過去のログを日時、データ対象を指定して参照できるようにする
まぁ、こんな感じかな。リングファイルというのは、ファイルにどんどんデータを書きこんでいって一定のサイズになったら書きこむポイントをファイルの先頭に移して古いデータに新しいデータを上書きしていくような仕組みのファイル構成だね。それで今回はそれが10万件を越えたら、と。1つのデータは18バイトの構造体データだから、全部で約1.8Mバイト。それでリアルタイムにデータが更新されるわけなんだけど、最新のデータが分かるようにちゃんとフラグも含まれていて、そのフラグが"1"なデータが10万件に1件だけ必ずあるから、そのデータを常に追いかけていけばリアルタイム監視部分はできるかな、と思ってる。こちらはまだ本組してないんで分からないけどね。この最新データは必ずシーケンシャル(順次)に書き換わるわけだから毎回10万件の中から探すのも大変だから、起動時に最新データを見つけ出しておいて、後はファイルの書き換わったのを検知したら覚えておいたポイントを参考にして探す、という方針で作ってる。起動時の最新データの検索はデータを最初から順番に調べていって最新フラグが"1"だったら…なんてことはもちろんしません。んなことしたら起動するだけで何秒かかることやら(笑)
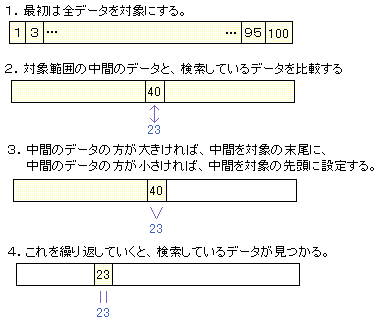
ま、一番分かりやすくて有効な高速検索アルゴリズムということで、二分探索方を使ってる。これならばlog
2100000 ≒ 16.6 だから最大17回の検索で見つけられるってことだね。これは自分で作ったダミーデータを読み込ませたところではちゃんと動作してる♪
それで次に取りかかったのが過去ログの部分。ここでちょっとつまった。これも起動時と同じで2分検索でいいかな〜、って思ったが単純にはいかなかった。2分検索ってのはデータが昇順か降順できちんと整列してないと使えないんけど、このリングファイルのデータ、1ヶ所だけそうじゃない部分があるから。そう最新データの部分。最新データの1つ前は最新データの次に新しいデータなんだけど、最新データの次のデータはいきなり最古のデータになっちゃう。起動時の探索ではフラグがあるおかげでなんとか誤魔化せてるけどここはそれでは出来ない。ん〜、どうしたものかとかなりいろいろ試してみたけど結局上手くいかず。仕方ないから帰ってゆっくり考えるかな、と思って会社を出る。

駅までの帰り道に歩きながら考える。すると何時間も考えて行き詰まってたのに、わずか2分後、答えらしきものが見つかった(笑) なんのことはない、「リングファイル」という特徴を最大限使えばいい、ってことだね。どうしてもプログラムするときに物理的なファイルを考えてしまってファイルの先頭から末尾までが範囲と考えちゃうけど、リングファイルは仮想的には末尾と先頭が繋がってることを考えれば、検索するときの範囲を素直に「最古のデータから最新のデータまで」にしてあげればちゃんと昇順になって問題ないんだよね。せっかく自分でも意図してかは忘れたけど(^^;;、物理的な境界を気にしないでファイルにアクセスできるようにプログラミングしてあったのにも関わらず、それを使わないで検索部分のコーディングでなんとかしようというのが間違いだったんだね。なんというか、見つかってしまえばなんでこんなことで悩んでいたんだ、って感じだね。煮詰まったときは無理に考えすぎないで、頭を休め、発想の転換をしたほうが良い、というのの最たる例となったのでありました、おしまい。あっ、まだ完成してないから続く、か。